How to use a SQL trigger for the wrong reason#
A couple of days ago I came onto a question on Stackoverflow asking how to create a trigger to impose constraints. The question asked about a SQL trigger where the OP (original poster) asked for, and I quote:
” I understand the idea of triggers but a bit confused on how to use it to impose constraints.
For example I have two tables: a student table and book_order table that shows what book a student orders. I want to create a trigger that will check that a student with a book order cannot be deleted from the student table.”
The request sounds simple and easily implementable with a SQL trigger, as the OP asked for, but it’s wrong and just because you can it doesn’t mean that you should. Although the question has gotten an answer which was also accepted, this solution is something which both I and others do not recommend.
What the OP should implement in this type of scenario is a foreign key constraint on the book order table, referencing the student table, and that’s it. That will perfectly fit the scenario which OP has described. All that he had to do is:
ALTER TABLE Book_Order
ADD CONSTRAINT FK_Student_Loaned_Books
FOREIGN KEY (Student_ID)
REFERENCES Student (ID);
Now, to detail a bit why a SQL trigger is not the better alternative.
What is a SQL trigger?#
A trigger is, as per Microsoft’s latest version of the documentation (12-Dec-2016) : “A trigger is a special kind of stored procedure that automatically executes when an event occurs in the database server. DML triggers execute when a user tries to modify data through a data manipulation language (DML) event. DML events are INSERT, UPDATE, or DELETE statements on a table or view. These triggers fire when any valid event is fired, regardless of whether or not any table rows are affected.“
From that definition we can see that by using a trigger, you trigger statements will fire each time there is a corresponding DML event on that table (in this case a DELETE), even if no rows are affected.
So, that means that the SQL trigger logic will execute even if no rows might get affected. And depending on how you write the statements inside the trigger to check if there are other rows in the other table before deleting, then the process might be slower or less performant than implementing a FK constraint. If you’re thinking that in both situations:
-
a DELETE from Student with FK constraint on Book_Orders
OR
-
a ON DELETE trigger that has a logic of checking if the student has any book loans
will hit the Book_Orders table, then you’re right and below is an example of a execution plan for a DELETE with a FK constraint.
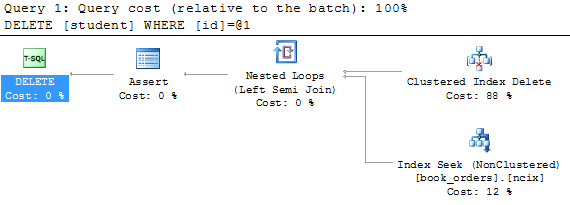
I’ve seen a lot of poorly written database code, especially code written in a procedural way rather than in a set based way or code that tries to bring in some advantages from OOP, but which do not work in a database.
You’re better off sticking with things that others have built and work well (that’s OOP’s code reusablity too, right?).
This scenario is another example of that, where although you are able to write a piece of code, in a way you’re thinking it will work, and it just might work too(!), but it doesn’t mean that it’s the right way.
You might end up writing some non-performant T-SQL code in that your SQL trigger that will do a FULL TABLE SCAN of the Student table or even worse, a FULL TABLE SCAN of the Book_Order table, which I’m expecting to be much bigger. And even if your database has a lot of RAM and can handle that, why not write good quality code that’s like a fine made Swiss watch or like a well sharpened knife?
SQL Server as well as other RDBMS systems have features in place that are very well implemented (by teams of experts) and implemented to work well with the entire database and although you can replace with “your-own-code goes here”, often times you’ll just end up beating the nail with the wrong end of a screwdriver (beating it with the handle).
You’ll get the job done, but in a way that you’re consuming more energy, more resources and might even hurt yourself in the process.